k8s&GPU Operator
k8s&GPU Operator
应用程序部署方式演变:

K8S简介
k8s 是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用的生命周期。
主要功能包括:
- 自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
- 弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
- 服务发现:服务可以通过自动发现的形式找到它所依赖的服务
- 负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
- 版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
- 存储编排:可以根据容器自身的需求自动创建存储卷
组件包括:
master:集群的控制平面,负责集群的决策 ( 管理 )
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
Scheduler : 负责集群资源调度,按照预定的调度策略将 Pod 调度到相应的 node 节点上
ControllerManager : 负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等
Etcd :负责存储集群中各种资源对象的信息,相当于 K8S 的数据库
node:集群的数据平面,负责为容器提供运行环境 ( 执行 )
Kubelet : 负责维护容器的生命周期,即通过控制docker,来创建、更新、销毁容器
KubeProxy : 负责提供集群内部的服务发现和负载均衡
Docker : 负责节点上容器的各种操作
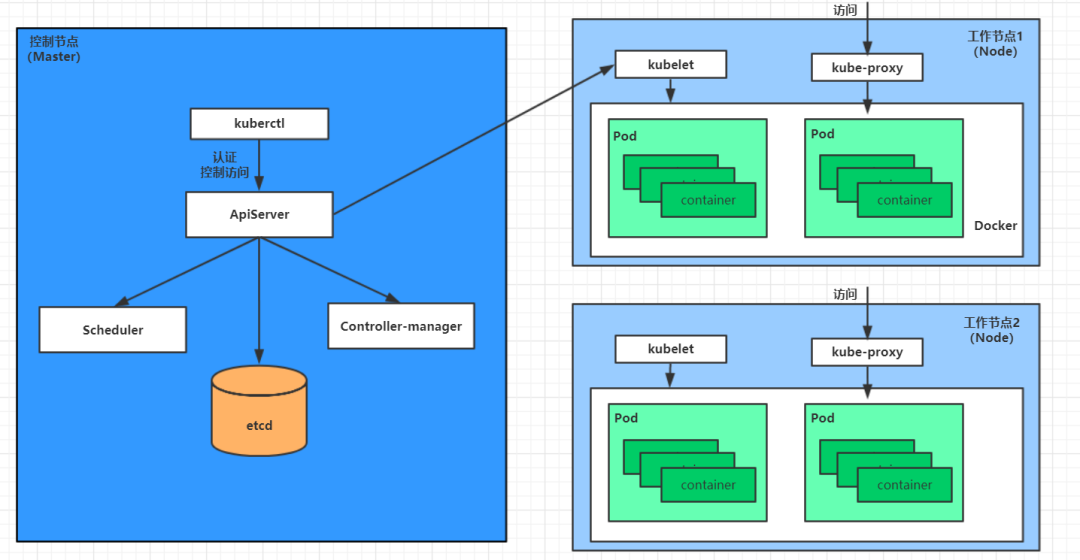
核心概念包括:
- Pod:Pod 是 k8s 管理的最小调度单位,它可以包含一个或多个容器,并共享网络和存储资源( IP 地址、端口、存储卷)。Pod 提供了容器之间的通信和协作。
- Deployment:Deployment 定义了应用程序的期望状态,并负责创建和管理 Pod 的副本。它支持滚动更新、回滚和扩缩容等操作。
- Service:Service 定义了一组 Pod 的访问方式和网络策略,为 Pod 提供了稳定的网络端点。Service 可以通过负载均衡将请求分发到后端的 Pod
- Namespace:Namespace 提供了一种逻辑隔离的机制,用于将集群中的资源划分为多个虚拟集群。不同的 Namespace 可以拥有独立的资源配额、访问控制策略等。
- Volume:Volume 是用于持久化数据的抽象,它可以在 Pod 之间共享和持久化存储数据。k8s 支持多种类型的 Volume,如本地磁盘、网络存储等。
K8S配置:
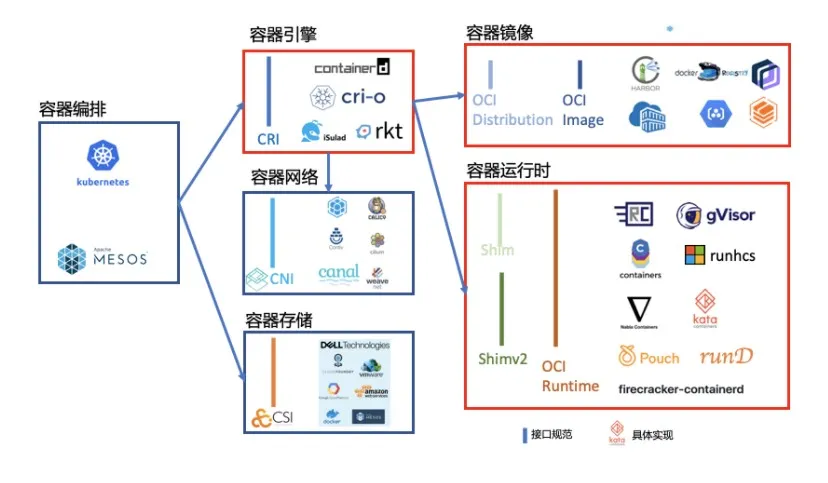
K8S早已不支持docker。K8S自己没有启动运行容器的能力,它里面不包含“容器引擎”(也就是Container Image的解释器),容器的启停与管理是交给第三方实现的,称为“容器运行时”。K8S制定了一个接口规范:CRI,用于给第三方参考实现容器运行时。具体来时,CRI是基于gRPC的进程间通讯协议。
容器运行时
常见的容器运行时有:
containerd
比Docker更受欢迎,是目前K8S的首选。
CRI-O
专用于K8S的精简版Docker,于是就有了它。
cri-dockerd
对接Docker Engine本尊。
安装containerd、runc、cni
以下全部在sudo su后,以root用户运行:
1
2
3
4
5
6
7
8
9
10
export VERSION="1.7.13"
apt install -y libseccomp2 wget
wget https://github.com/containerd/containerd/releases/download/v${VERSION}/cri-containerd-cni-${VERSION}-linux-amd64.tar.gz
wget https://github.com/containerd/containerd/releases/download/v${VERSION}/cri-containerd-cni-${VERSION}-linux-amd64.tar.gz.sha256sum
sha256sum --check cri-containerd-cni-${VERSION}-linux-amd64.tar.gz.sha256sum
tar --no-overwrite-dir -C / -xzf cri-containerd-cni-${VERSION}-linux-amd64.tar.gz
systemctl daemon-reload
systemctl enable containerd
配置containerd使用代理,修改/etc/systemd/system/containerd.service 此处在project环境配置
1
2
wget https://github.com/opencontainers/runc/releases/download/v1.1.12/runc.amd64
install -m 755 runc.amd64 /usr/local/sbin/runc
生成containerd的配置文件 /etc/containerd/config.toml:
1
2
mkdir -p /etc/containerd/
containerd config default > /etc/containerd/config.toml
然后修改一处的配置:
1
2
3
4
# ...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true # 原本是 false,不改的话容器时不时会崩溃
# ...
启动containerd:systemctl daemon-reload、systemctl start containerd
安装完毕后跑个hello world镜像看看:
1
2
ctr image pull docker.io/library/hello-world:latest
ctr run --rm docker.io/library/hello-world:latest hello-world
containerd常用命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
# 查看镜像 ctr image list 或者 crictl images # 拉取镜像, 分为非k8s容器用 和 k8s容器用。一定要加上--all-platforms ctr i pull --all-platforms registry.xxxxx/pause:3.2 ctr -n k8s.io i pull --all-platforms registry.aliyuncs.com/google_containers/pause:3.2 或者,要登录的harbor ctr i pull --user user:passwd --all-platforms registry.aliyuncs.com/google_containers /pause:3.2 或者,不推荐,没有 --all-platforms crictl pull --creds user:passwd registry.aliyuncs.com/google_containers /pause:3.2 # 镜像打tag 镜像标记tag ctr -n k8s.io i tag registry.xxxxx/pause:3.2 k8s.gcr.io/pause:3.2 或者 强制覆盖 ctr -n k8s.io i tag --force registry.xxxxx/pause:3.2 k8s.gcr.io/pause:3.2 # 删除镜像tag ctr -n k8s.io i rm registry.xxxxx/pause:3.2 # 推送镜像 ctr i push --all-platforms --user user:passwd registry.xxxxx/pause:3.2 # 导出/保存镜像 ctr -n=k8s.io i export kube-apiserver:v1.28.0.tar xxxxx.com/kube-apiserver:v1.28.0 --all-platforms ctr -n=k8s.io i import kube-apiserver:v1.28.0.tar
基础配置
- 禁用swap
1
2
3
4
#关闭swap
sudo swapoff -a
#注释swap行
sudo sed -ri 's/.*swap.*/#&/' /etc/fstab
- 网络设置
1
2
3
4
5
6
7
sudo su
cat > /etc/sysctl.d/k8s.conf << EOF
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
EOF
sysctl --system
安装K8S
下载kubeadm
1 2 3 4 5 6 7 8 9 10 11
sudo apt-get update # apt-transport-https 可能是一个虚拟包(dummy package);如果是的话,你可以跳过安装这个包 sudo apt-get install -y apt-transport-https ca-certificates curl gpg # 如果 `/etc/apt/keyrings` 目录不存在,则应在 curl 命令之前创建它,请阅读下面的注释。 # sudo mkdir -p -m 755 /etc/apt/keyrings curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.29/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg # 此操作会覆盖 /etc/apt/sources.list.d/kubernetes.list 中现存的所有配置。 echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.29/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list sudo apt-get update sudo apt-get install -y kubelet kubeadm kubectl sudo apt-mark hold kubelet kubeadm kubectl
运行
kubeadm init(可用kubeadm reset重置)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 10.19.61.125:6443 *-*-token vcdzjw.sr64wi1mkpe5bz5s \ --discovery-token-ca-cert-hash sha256:738c33d369e2987f33a7f51d353ec2e853265ef2e045ab6f5506da36ef471ec0
部署k8s
Kubernetes API 服务器以及整个 Kubernetes 集群完全可以在单台服务器上进行配置和运行,这种方式通常用于开发、测试或学习 Kubernetes 的基本概念。通常,我们将这种部署方式称为 单节点集群 或 单机集群。
- 执行
sudo kubeadm init --pod-network-cidr=192.168.0.0/16其中,--pod-network-cidr=192.168.0.0/16是给 Pod 网络分配的地址范围,具体的值取决于你使用的网络插件。例如,如果使用的是 Calico,可以保持默认值。 初始化完成后,需要将 kubeconfig 配置文件复制到的用户目录,这样kubectl就能连接到集群:
1
2
3
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
- 安装网络插件以支持pod互相通信(Calio或Flannel)
1
kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
- 检查集群状态,status必须为ready,如果notready可以
sudo systemctl restart kubelet
1
2
3
(base) hjy@debian:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
debian Ready control-plane 5m26s v1.29.11
如果有其他节点加入集群,可以使用下列命令。由于此时为单节点集群,无需操作。
1
kubeadm join --token <token> <master-ip>:<port> --discovery-token-ca-cert-hash sha256:<hash>
K8S API服务器启动
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制 启动 Kubernetes API 服务器(kube-apiserver)通常是在 Kubernetes 集群初始化时由 Kubernetes 控制平面管理的。在大多数生产环境中,API 服务器会通过 Kubernetes 集群的控制平面自动启动和管理。如果你正在手动管理一个 Kubernetes 集群,或者在某些开发环境中工作,可能需要手动启动 Kubernetes API 服务器。
sudo kubeadm init --pod-network-cidr=192.168.0.0/16自动启动了K8S API服务器,可以查看服务器状态,并能够看见kube-apiserver相关的 Pod
1
2
3
4
5
6
7
8
9
10
11
12
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-658d97c59c-d5htd 1/1 Running 0 13m
calico-node-hd5jm 1/1 Running 0 13m
coredns-76f75df574-2mbvl 1/1 Running 0 18m
coredns-76f75df574-nzljv 1/1 Running 0 18m
etcd-debian 1/1 Running 1 18m
kube-apiserver-debian 1/1 Running 1 18m
kube-controller-manager-debian 1/1 Running 1 18m
kube-proxy-djns7 1/1 Running 0 18m
kube-scheduler-debian 1/1 Running 1 18m
- 如果你的
kubectl配置文件中错误地将 API 服务器指向localhost:8080,你需要更新配置文件,使其指向正确的 Kubernetes API 服务器地址.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#查看当前配置
kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://10.19.61.125:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: DATA+OMITTED
client-key-data: DATA+OMITTED
#修改API服务器地址设置
kubectl config set-cluster my-cluster --server=https://<your-kubernetes-api-server>:6443
- 如果你确实需要将 Kubernetes API 服务器的端口号修改为其他端口,可以在 Kubernetes 配置中修改
--port或--secure-port参数,但这种修改通常需要集群管理员权限。更常见的做法是修改客户端kubectl配置文件,指向正确的 API 服务器地址和端口。 - 如果 Kubernetes 集群部署在远程机器上,确保防火墙没有阻止访问 Kubernetes API 端口(通常是 6443 或其他配置的端口)
手动安装(没实操,用于调试不建议)
kube-apiserver是 Kubernetes 控制平面的一部分,通常与kube-controller-manager和kube-scheduler一起运行。-advertise-address是 Kubernetes API 服务器的公网 IP 地址,通常是控制平面节点的 IP。-secure-port=6443用于 HTTPS 通信,通常使用 6443 端口。-insecure-port=8080用于 HTTP 通信,一般不推荐开放。-etcd-servers用于指定 Etcd 集群的地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
#启动APIserver kube-apiserver \ --advertise-address=<API_SERVER_IP> \ --bind-address=0.0.0.0 \ --insecure-port=8080 \ --secure-port=6443 \ --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname \ --authorization-mode=Node,RBAC \ --enable-bootstrap-token-auth \ --service-cluster-ip-range=<Service_IP_Range> \ --etcd-servers=http://<etcd-server-ip>:2379 #启动APIserver作为后台进程 nohup kube-apiserver \ --advertise-address=192.168.1.100 \ --bind-address=0.0.0.0 \ --secure-port=6443 \ --etcd-servers=http://127.0.0.1:2379 \ --authorization-mode=Node,RBAC \ --service-cluster-ip-range=10.96.0.0/12 \ --allow-privileged=true &
- 检查API server状态
1
2
3
4
5
6
kubectl get componentstatuses
#正常启动
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy ok
总流程为:
containerd能正常运行→kubeadm init→创建kubelet
GPU Operator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
helm install --wait --generate-name \
-n kube-system \
nvidia/gpu-operator
gpu-feat*ure-discovery-jdqpb 1/1 Running 0 35d
gpu-operator-67f8b59c9b-k989m 1/1 Running 6 (35d ago) 35d
nfd-node-feature-discovery-gc-5644575d55-957rp 1/1 Running 6 (35d ago) 35d
nfd-node-feature-discovery-master-5bd568cf5c-c6t9s 1/1 Running 6 (35d ago) 35d
nfd-node-feature-discovery-worker-sqb7x 1/1 Running 6 (35d ago) 35d
nvidia-container-toolkit-daemonset-rqgtv 1/1 Running 0 35d
nvidia-cuda-validator-9kqnf 0/1 Completed 0 35d
nvidia-dcgm-exporter-8mb6v 1/1 Running 0 35d
nvidia-device-plugin-daemonset-7nkjw 1/1 Running 0 35d
nvidia-driver-daemonset-5.15.0-105-generic*-ubuntu22.04-g5dgx 1/1 Running 5 (35d ago) 35d
nvidia-operator-validator-6mqlm 1/1 Running 0 35d
出现一个completed,其他为running即为成功(注意核对pod是否部署完全)
测试
创建yaml文件
1
2
3
4
5
6
7
8
9
10
11
12
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1
kubectl apply -f cuda-vectoradd.yaml 创建pod,kubectl get pod -A pod状态为completed
1
2
3
4
5
6
7
8
kubelet logs pod cuda-vectoradd
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
坑
- 单节点在control plane上调度pod需要 对NoSchedule untainted
1
2
kubectl taint nodes debian node-role.kubernetes.io/control-plane:NoSchedule-
node/debian untainted
- 磁盘空间不足
df -h更换数据挂载位置(以containerd为例)
1
sudo chown -R root:root /mnt/sdb/home/hjy/data/containerd
编辑 /etc/containerd/config.toml 添加
1
2
root = "/mnt/sdb/home/hjy/data/containerd"
state = "/mnt/sdb/home/hjy/data/containerd-state"
- image问题
ctr对一些镜像无法拉取,可以先用docker pull拉取
1
2
3
4
docker pull pytorch/pytorch:2.4.1-cuda11.8-cudnn9-runtime
#然后导入containerd
docker save pytorch/pytorch:2.4.1-cuda11.8-cudnn9-runtime -o pytorch.tar
ctr -n k8s.io images import pytorch.tar
- 使用minikube
1
2
minikube start --driver docker --container-runtime docker --gpus all
minikube start --driver docker --container-runtime docker --gpus all --memory=8192 --cpus=4
同时安装GPU Operator(注意安在kube-system的域名中)
安装前先minikube ssh查看是否有NVIDIA驱动,start时指定了GPU所以无需安装driver
1
2
3
4
5
6
7
8
9
10
11
12
13
helm install --wait --generate-name \
-n kube-system \
nvidia/gpu-operator\
--set driver.enabled=false
kube-system gpu-operator-1733749168-node-feature-discovery-gc-56b774c9cs4bg 1/1 Running 0 20m
kube-system gpu-operator-1733749168-node-feature-discovery-master-576bhrxgx 1/1 Running 0 20m
kube-system gpu-operator-1733749168-node-feature-discovery-worker-gpjss 1/1 Running 0 20m
kube-system gpu-operator-6b5d94cf79-b4zxs 1/1 Running 0 20m
kube-system nvidia-container-toolkit-daemonset-ll5kk 1/1 Running 0 17m
kube-system nvidia-cuda-validator-7pghq 0/1 Completed 0 17m
kube-system nvidia-device-plugin-daemonset-8nhq6 1/1 Running 0 33m
kube-system nvidia-operator-validator-gkrpc 1/1 Running 0 18m
必须安装GPU Operator才能申请GPU资源,minikube可以满足(但功能不齐全)
- minikube无法应用在hami上
部署hami应用时hami-device-plugin-q8t8d 状态一直为error
1
2
kubectl logs -n kube-system hami-device-plugin-czl7q
Defaulted container "device-plugin" out of: device-plugin, vgpu-monitor
即minikube在安装GPU Operator时并未安装vgpu-monitor,无法启动容器